Power Automateで文字列抽出
Power Automateで文字列抽出
最近Power Automateの記事をよく書いますが、基本的に何か一連の機能を作成する流れを説明していることが多いです。
その中で出てくる各機能の詳細についてはあまり触れられていない事が多いので、今回は機能の詳細について説明する機会があっても良いかなと思いました。
なので今回は前回作成したPower Automateでファイルバックアップ(OneDrive)で使用した「ファイル名の文字列から拡張子を抽出する機能」について、詳細をまとめようと思います。
正規表現のような機能を作るのはまだ難しいですが、拡張子のようにある程度事前に抽出する文字列が定まっていれば数ステップで機能実装が可能です。
ステップや使用している関数の内容について説明していきます!!
各関数の説明
それでは、文字列を抽出するために使用する関数の説明をしていきます。今回は分かりやすくするためにファイル名から拡張子を抽出する流れで説明します。
- lastIndexOf
- 「.html」の開始位置を取得する
- 「.」の開始位置取得を取得する
- sub
- substring
まず文字列を抽出するためには、抽出対象の文字列の開始位置が必要になります。なので開始位置が文字列の何番目から開始するのかを取得します。
その際に使用する関数がlastIndexOfになります。
引数は2つ指定します。
・第一引数:対象文字列
・第二引数:抽出したい文字列
※抽出したい文字列が対象文字列に複数存在する場合は、最後に検知された開始位置が戻り値として返されます。最初に見つかった場所が欲しい場合にはindexOfを使用します。
それではlastIndexOfを使用したテストを実施してみましょう。今回対象にする文字列は「index.html.20211017」で、変数strに格納しています。この文字列に対して「.html」を指定して開始位置を取得する場合と「.」のみを指定して開始位置を取得する2パターンを実施します。結果は下記になります。
第一引数は「variables('str')」、第二引数に「.html」を指定します。
・lastIndexOf(variables('str'),'.html')
その結果が下記で「5」が返ってきます。

第一引数は「str」、第二引数に「.」のみを指定します。
・lastIndexOf(variables('str'),'.')
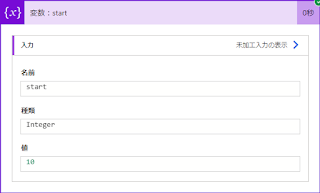
その結果が下記で「10」が返ってきます。
抽出したい文字列の開始位置が取得できたら次は、抽出したい文字列の長さを取得する必要があります。
その際に使用するのがsubになり、この関数は第一引数の値から第二引数の値を引き算した値が返ってきます。なので指定する引数は下記になります。
・第一引数:対象文字列の長さ
・第二引数:抽出したい文字列の開始位置
なおこの部分は、抽出した文字列の文字数が予めわかっている場合には必要なく、直接変数などに値を格納して置くだけで良いです。
先程のlastIndexOfで第二引数に「.」を指定した続きでテストしてみましょう。なおlastIndexOfの結果は変数startに格納しています。
subに指定する引数は、第一引数に「length(variables('str'))」、第二引数には「variables('start')」になります。なおlength関数は単純に文字列の長さを返してくれる関数です。
・sub(length(variables('str')),variables('start'))
結果としては下記のうように「9」が返ってきます。

抽出したい文字列の開始位置と長さまで取得できれば、最後はその2つを使用して対象文字列から抽出を行います。
そこで使用するのがsubstringで、第一引数に指定した文字列に対して、第二引数の開始位置から第三引数の長さ分の文字列を抽出します。
・第一引数:対象文字列
・第二引数:抽出したい文字列の開始位置
・第三引数:抽出したい文字列の長さ
subで返ってきた値は変数lengthに格納しています。
substringに指定する引数は、第一引数に「length(variables('str'))」、第二引数には「variables('start')」、第三引数には「variables('length')」です。
・substring(variables('str'),variables('start'),variables('length'))
結果として、「.20211017」が返ってきます。

まとめ
ということで今回は、文字列から指定の文字列を抽出する方法について、各関数の説明をまとめました。
文字列抽出は色々な場面で使うことがある機能だと思うので、覚えておいて損はないと思います!
ただ、文字列抽出だけでこんなにステップを踏まないといけないのは正直めんどくさいです。。ローコードを謳っているなら文字列抽出の関数を用意しておいて欲しいのが感想です。Power Automateはローコードでありながらある程度のプログラムを知っていないとできないのが惜しいところです。
なので、これからもPower Automateで使用できるステップなどをまとめていきたいと思います。
今回はこの辺で、ではまた!!



コメント
コメントを投稿